This tutorial will teach you how to load a CSV file into AWS Athena so that you can analyze it using SQL queries. This process will work for any CSV file, but in this tutorial we'll be using the free version of our World Cities Database. You could also use it with any of our many geographic databases. Let's get started
Login or create an AWS Account.
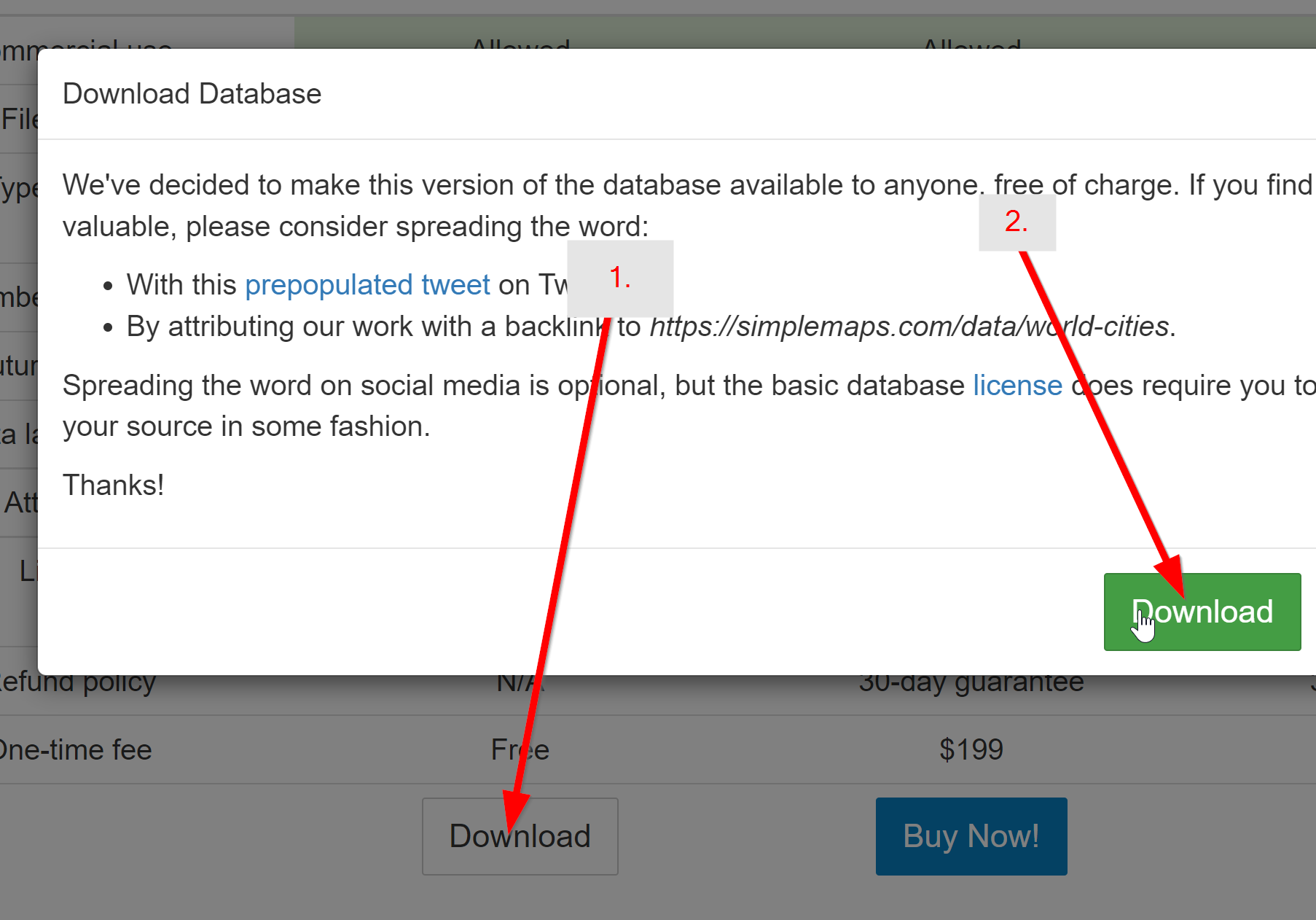
Download the Basic World Cities Database.
This is free and won't require you to provide any information. However, attribution is required. After downloading, unzip the folder. We'll be using the worldcities.csv file.
Clean and format the CSV as needed.
The CSV file should be encoded as UTF-8. Due to the way Athena parses CSV files, we also need to remove all quotes from the CSV file. The easiest way to do this is to open the CSV file in LibreOffice:
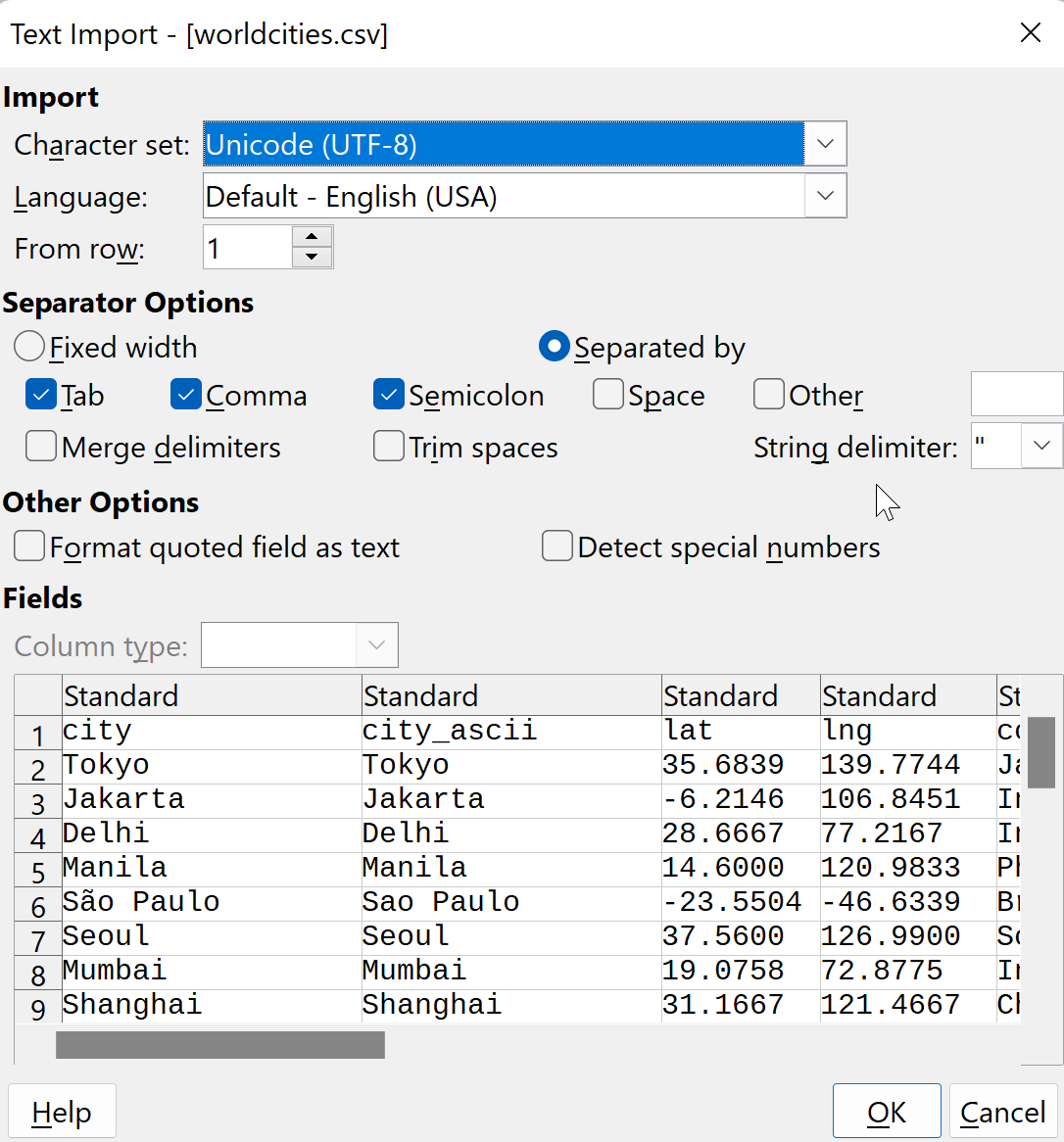 and then save it. Note the absence of quotation marks.
and then save it. Note the absence of quotation marks.
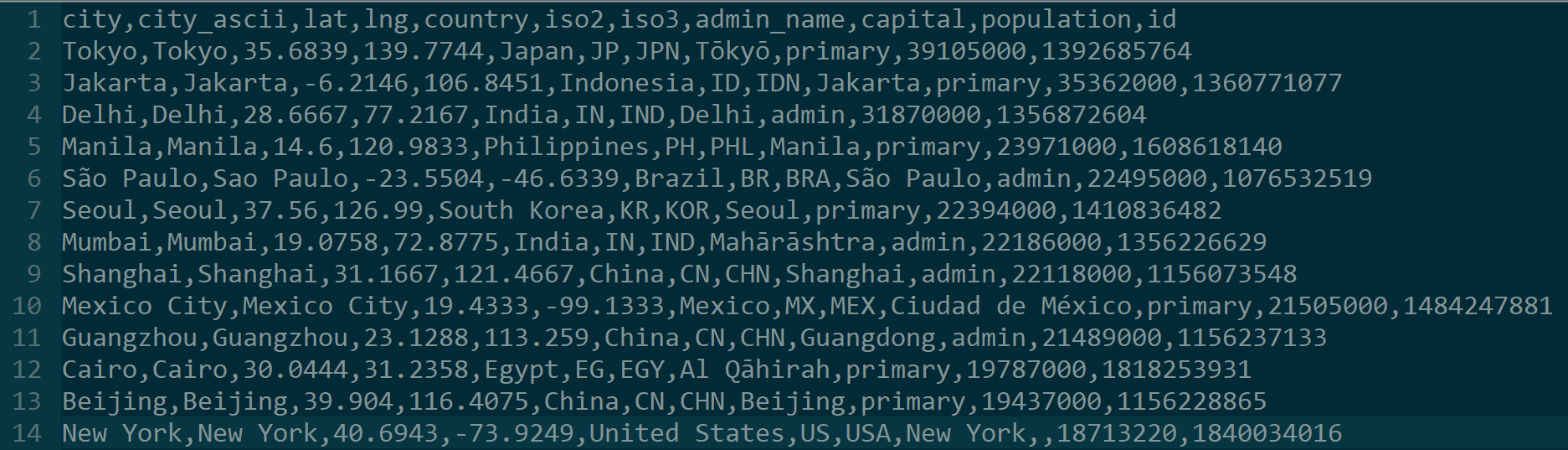 If you just want the CSV file after this has been done, you can download it here. Note: Do not try to do this with Excel because it does not handle UTF-8 characters well.
If you just want the CSV file after this has been done, you can download it here. Note: Do not try to do this with Excel because it does not handle UTF-8 characters well.
Create a new AWS S3 Bucket. We'll use the name simplemaps-example-athena. You will need to use a unique name of your own.
 Use all of the default settings.
Use all of the default settings.
Create two folders in the bucket: input and queries. Athena will use the queries folder to store the queries it runs.
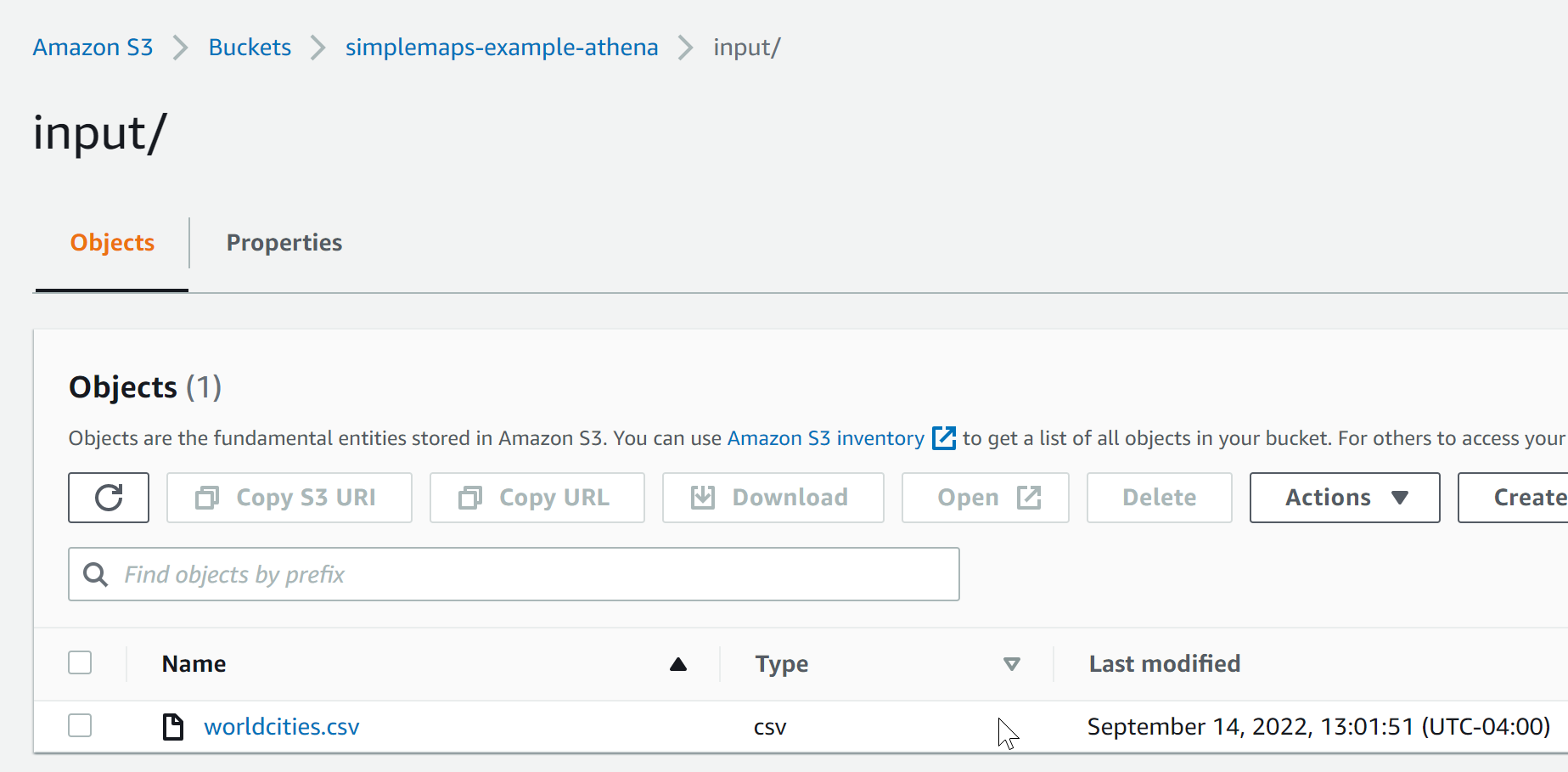
Upload the worldcities.csv file to the input folder you just created.
If you did things correctly, your bucket should look like this:
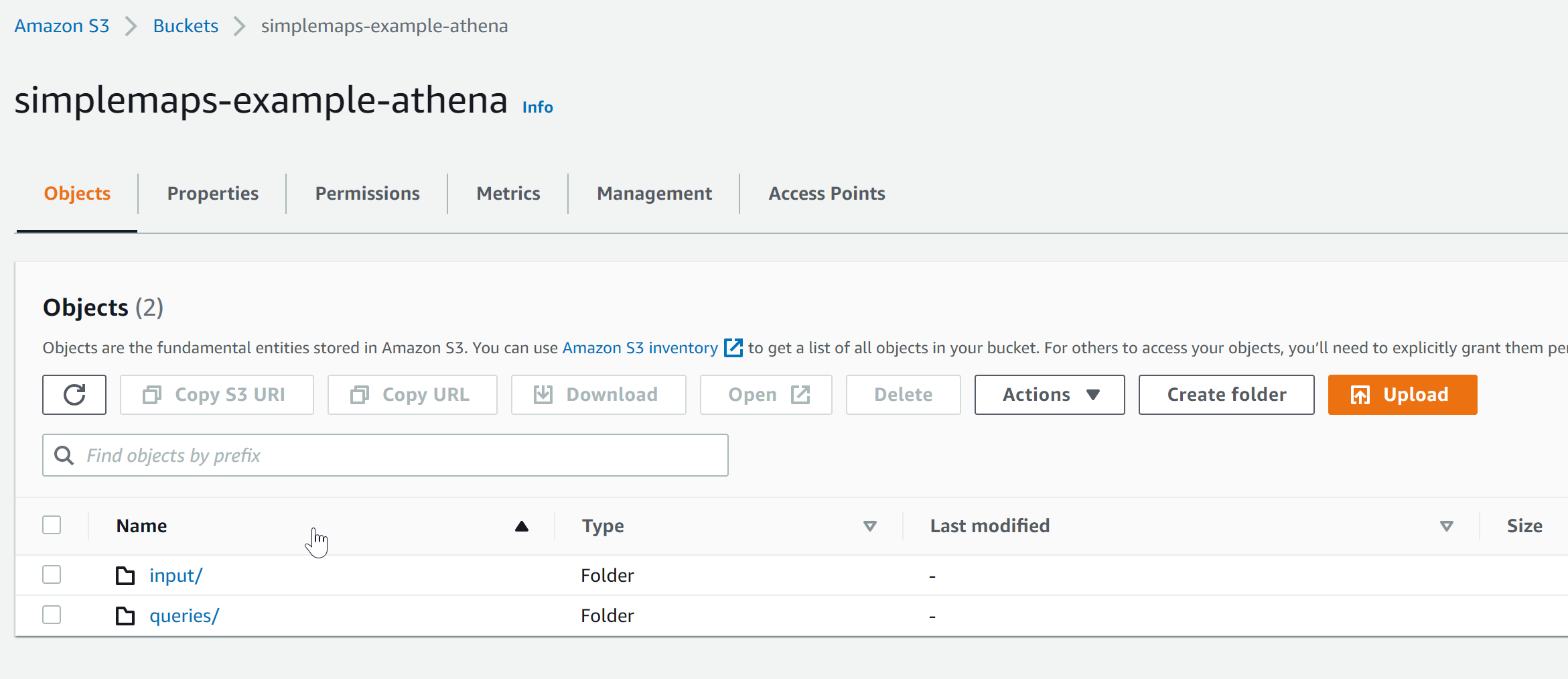 and the input folder should look like this:
and the input folder should look like this:
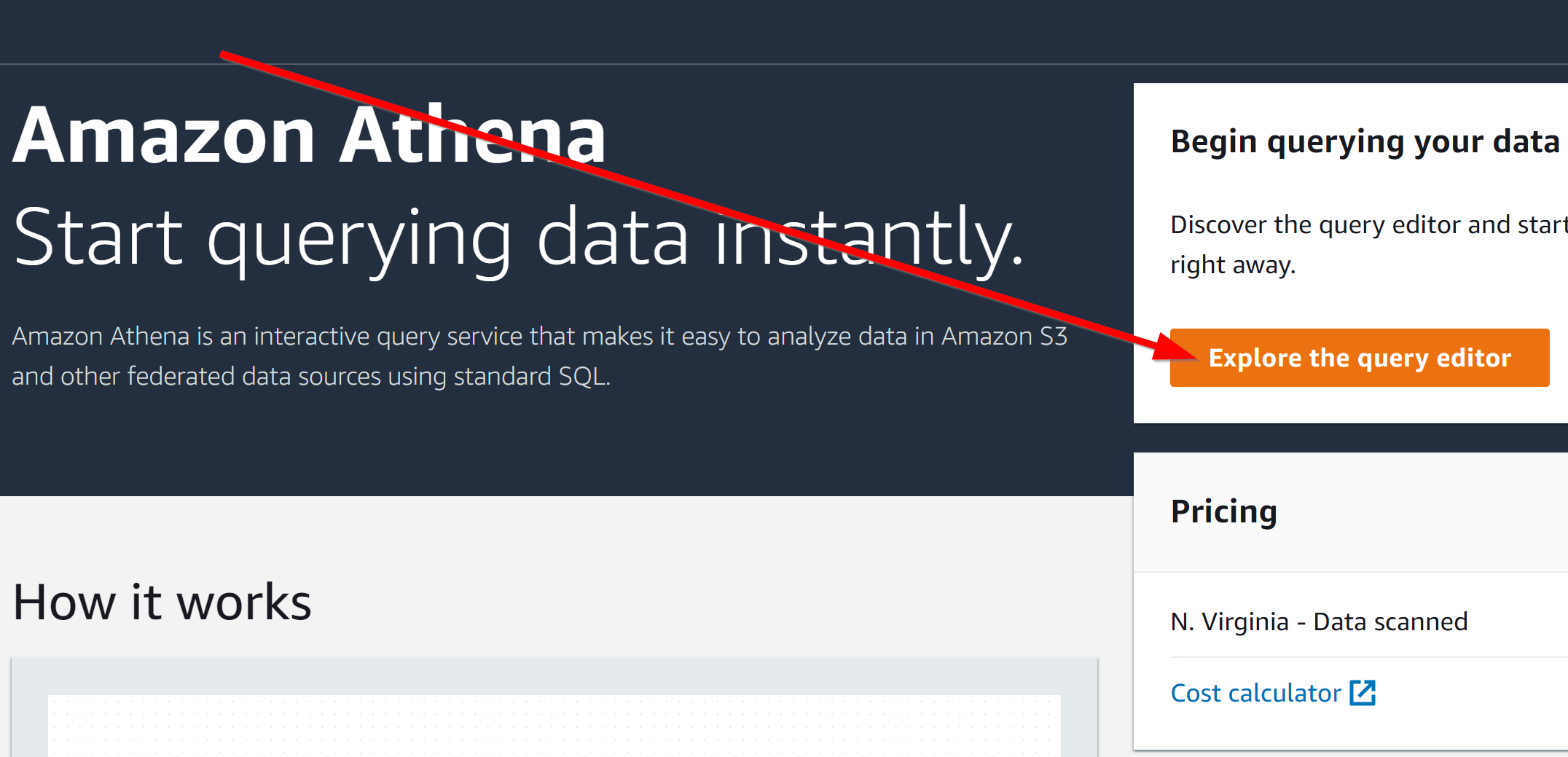
Open Amazon Athena and click Explore the Query Editor.
Go to the Settings tab and set the location of the query result to be s3://simplemaps-example-athena/queries. Except, of course, use your own unique bucket name.
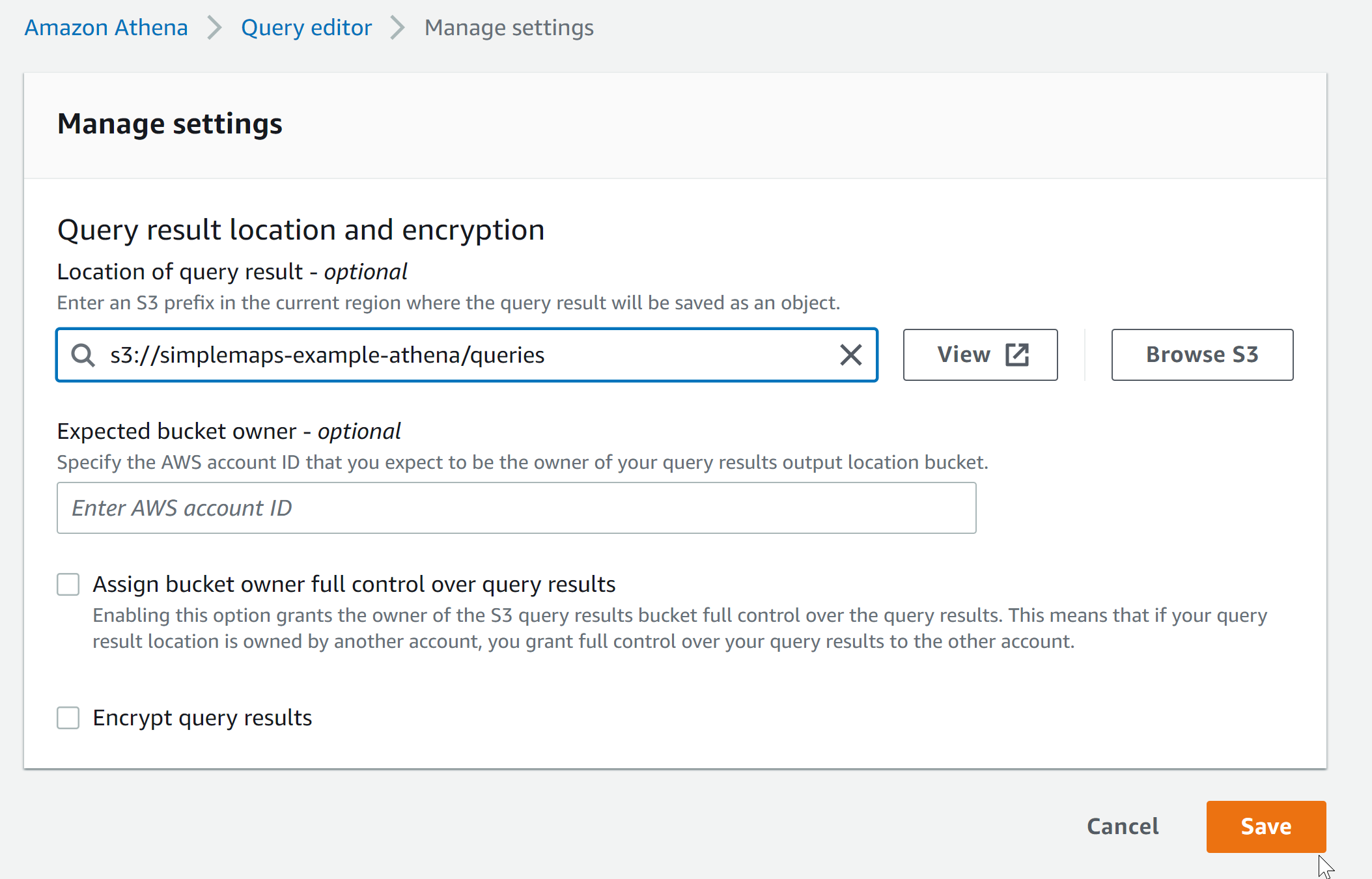 This is where Athena will store the queries that it runs.
This is where Athena will store the queries that it runs.
It's possible to import the data using the "Create" button, but we will import the data using a Query. Paste the following into the query area:
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`worldcities` (
`city` string,
`city_ascii` string,
`lat` double,
`lng` double,
`country` string,
`iso2` string,
`iso3` string,
`admin_name` string,
`capital` string,
`population` int,
`id` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
LOCATION 's3://simplemaps-example-athena/input/'
TBLPROPERTIES ('skip.header.line.count'='1')
;
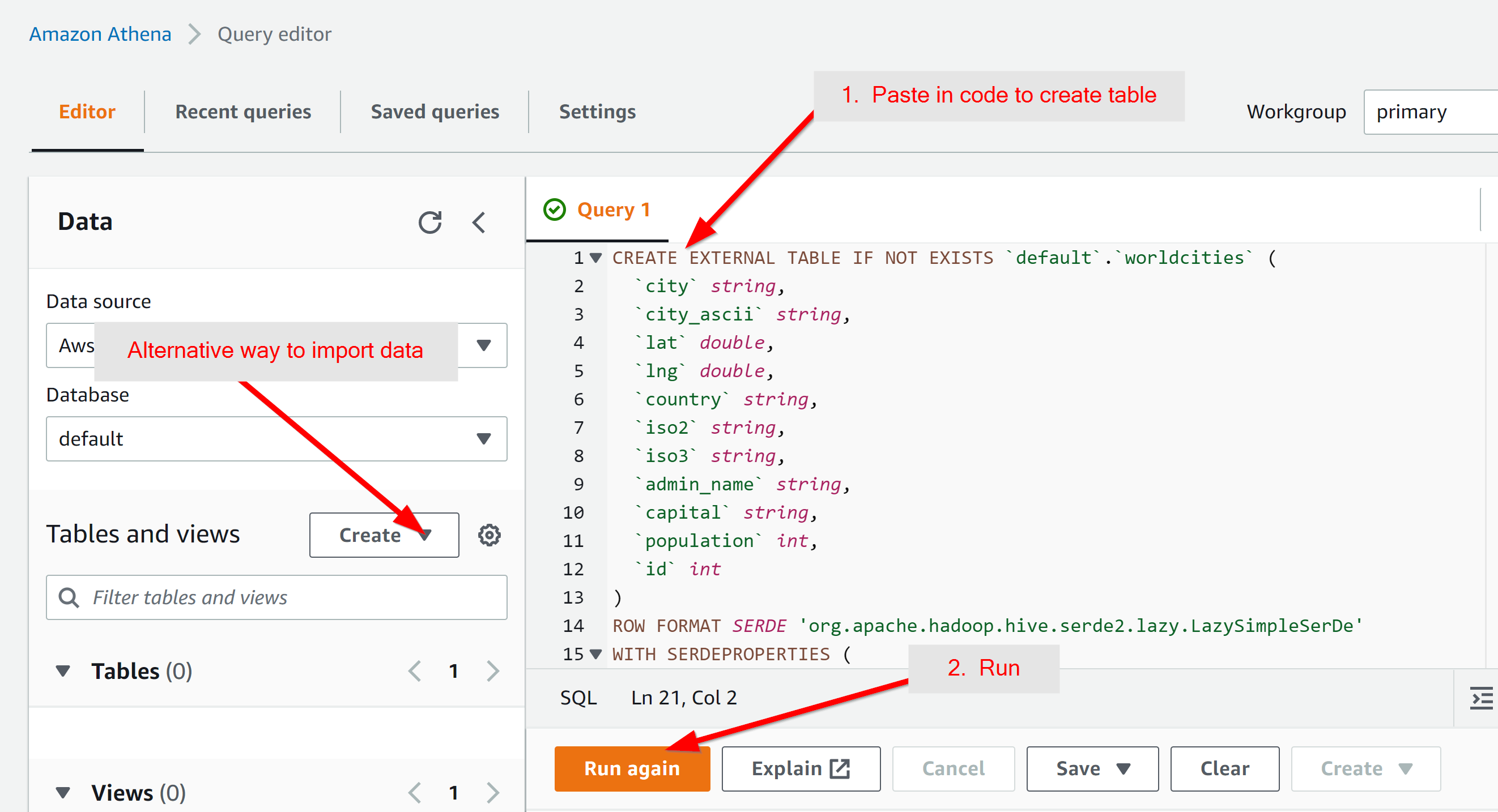
A few things to note on what this does:
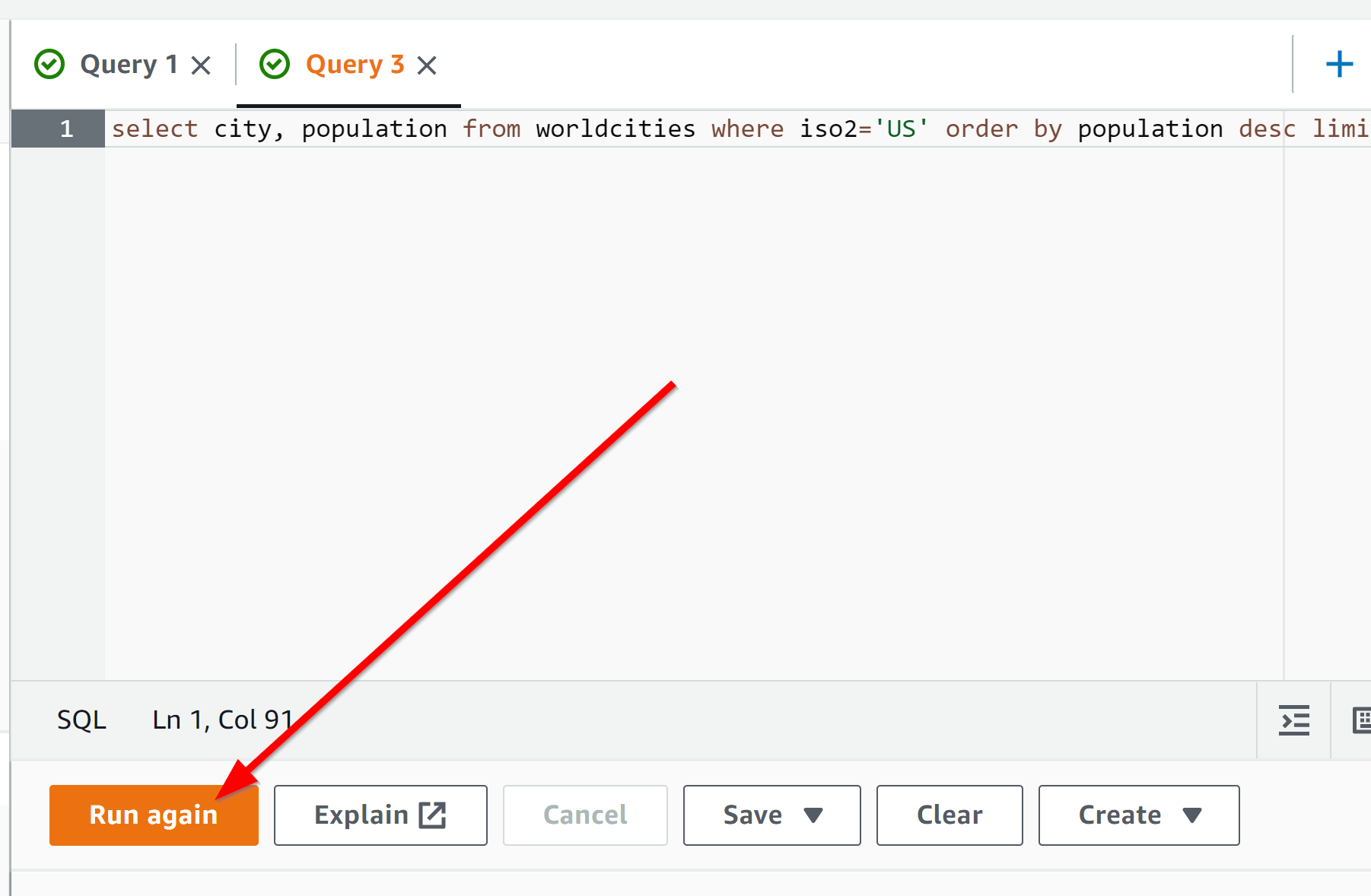
select city, population from worldcities where iso2='US' order by population desc limit 5;
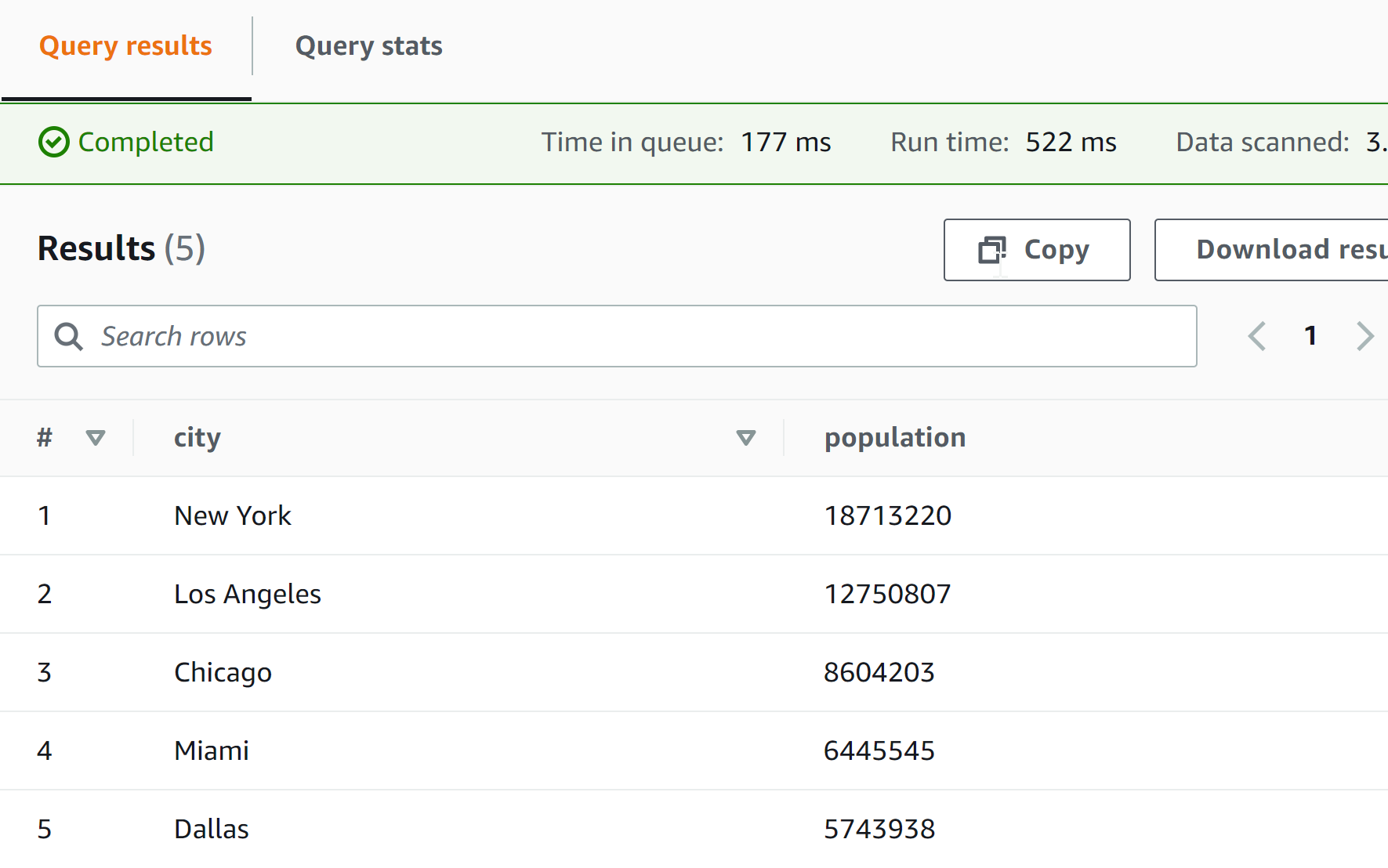
 and you should get the five largest cities in the United States:
and you should get the five largest cities in the United States:
Home (Maps) | Database License | Privacy | Database Releases | Database Order Lookup | Resources | Contact | FAQs
Popular Resources: Free SVG Maps | Free GIS Files | Free Cities Data | Zip Code Visualizations | Trauma Centers by State | Geography Quizzes
SimpleMaps.com is a product of Pareto Software, LLC. © 2010-2026.